前置芝士
概念 & 性质
处理一棵树会比较棘手,但是如果我们有办法把这棵树处理成一条一条的链,那就好解决多了。
树链剖分,简称树剖,就是干的这事。树链剖分有两种方法:重链剖分和长链剖分。因为长链剖分不常用,所以这一篇介绍的的都是重链剖分。
在了解接下来的内容之前,先要了解几个概念。
- 重儿子:每个子树中,子树大小(即子树包含节点数)最大的子节点
- 轻儿子:除重儿子外的其他子节点
- 重边:每个节点与其重儿子间的边
- 轻边:每个节点与其轻儿子间的边
- 重链:重边连成的链
- 轻链:轻边连成的链
大家发现没有,这里有三组相对的概念。为了更好的理解这几个概念,让我们在 mjl 的 PPT 上白嫖一棵树过来:
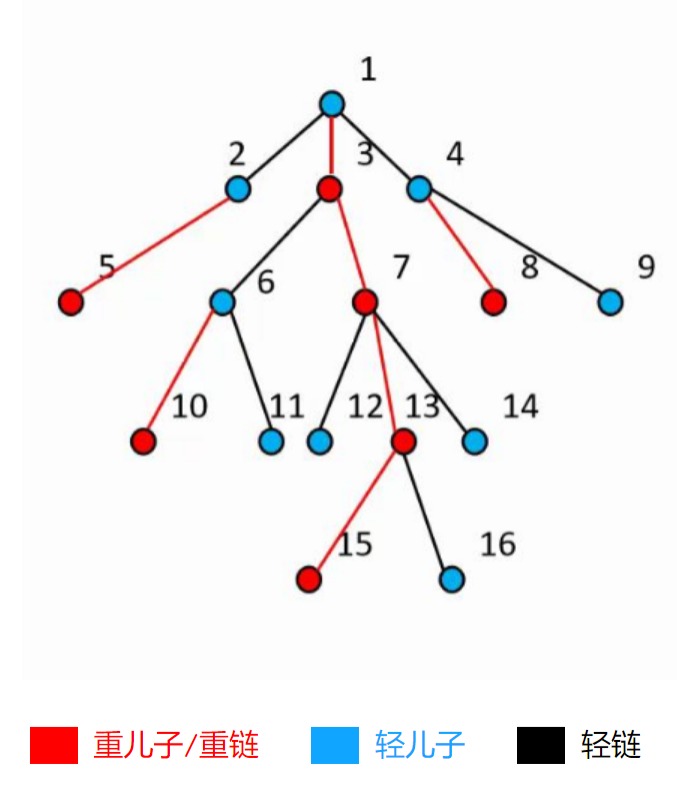
因为单独一个节点也可以看作重链,所以这棵树上的重链分布如下:

颜色标出来应该就很清晰了,每一条重链的链头都是轻儿子,后面全部都是重儿子。
因为 Hexo 对 $\LaTeX$ 的支持很不友好,所以窝直接从 luogu 的博客上截图截下来了 qwq。
除了上面说的,重链还有几个性质:
- 每一个节点只能在一条重链上,而且必定在重链上。(原因:每个节点只有一个重儿子。)
- 一个点到根节点的路径上最有只有 $\log n$ 条轻边。(原因:若 $v$ 为 $u$ 子节点且 $(u,v)$ 为轻边,则子树大小 $2sum_v\le sum_u$。)
树链剖分の基本解法
两个 DFS 预处理
既然每一条重链的头都是轻儿子,我们可以通过标记每一个节点所在重链的链头节点的方法来存储重链。在此之前,我们要开几个数组:
- $ft_u$: $u$ 的父节点;根节点 $ft_1=0$
- $dep_u$: $u$ 节点的深度
- $sum_u$: 以 $u$ 为根节点的子树的大小
- $son_u$: $u$ 的重儿子;叶子节点 $son_u=0$
- $top_u$: $u$ 所在重链的链头节点
第一个 DFS 需要做以下事情:
- 初始化每一个节点的父节点 $ft$,深度 $dep$ 和子树大小 $sum$;
- 求出每一个非叶子节点的重儿子 $son$。
代码长这样:
1 | void dfs1(int u, int fa) { // u 为遍历到的节点,fa 为 u 的父节点 |
第二个 DFS 的任务很简单:
- 算出 $top$ 数组。
- (可选)如果后面需要用 dfs 序(可能性很大)也需要求一下。
代码长这样:
1 | void dfs2(int u, int fa, int tp) { // u、fa 含义同上,tp 为目前重链的链头 |
这个代码遗留了两个问题:
为什么 dfs 序只需要加一次节点?
A:其实加一次或者两次两种写法都是对的,加一遍会更方便,两遍对于子树的更新思考起来比较好想出来,下文讲解使用加一遍的方法,两种写法的代码都有,供参考。
为啥要先搜重儿子?
A:为了让 dfs 序中每一条重链都连在一起,重儿子之间没有轻儿子捣乱,方便后面跳重链的时候用线段树维护。
树链剖分の妙用
1. 求 LCA
详情请见 LCA 文章中的树剖解法。
2. 在树上维护线段树
利用树剖把树转换为线性的链的特征,结合 dfs 序,可以利用树剖在树上维护线段树,从而达到一些目的。
要求维护的操作是两点之间的简单路径和子树的修改与查询,很明显可以用 dfs 序把树转换为数组再用线段树维护。
首先子树比较好操作,因为 dfs 序中子树是连在一起的,故以 $u$ 为根节点的子树在 dfs 序中的范围就是 $[id_u,id_u+sum_u-1]$,用区间修改、区间查询的线段树维护即可。
维护两节点之间的简单路径需要参考求 LCA 的方法,因为 $u,v$ 跳上去的路径就是这条简单路径。由于 $u,v$ 在跳到一条重链上之前都是一条一条跳重链,所以我们可以一边跳一边用线段树维护这些重链。最后两节点到一条重链上之后,再维护两节点之间的区间即可。我们生成 dfs 序的规则保证了这些区间都是连续的。
代码还挺难打的,我调了一个上午/kk。
1 | /** |
变式:
-
这个题目应该比板子简单,甚至都不需要区间修改,线段树维护一个结构体即可。敲代码的时候注意:
- 注意检查线段树有没有挂。
- 节点权值有可能是负数。所以记得求最大值的时候把初始值赋为极小值。
- 打线段树的时候可以巧用运算符重载,比如我是这么写的:
1
2
3
4struct _ {
int s, m;
_ operator+(const _ &x) const { return (_) { s + x.s, max(m, x.m) }; }
} t[maxn << 2], empty;
-
几乎和模板一样,只是查询多了一个到根节点的询问,这个函数传参变一下就行了。当然,如果明确知道其中一个节点是根节点,树链剖分也可以这么写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16inline void Update(int x, int k) {
while(x) { // 直接跳 x 即可,不用考虑根节点
update(1, 1, tot, id[top[x]], id[x], k);
x = ft[top[x]];
}
return;
}
inline int Query(int x) {
int s = 0;
while(x) {
s += query(1, 1, tot, id[top[x]], id[x]);
x = ft[top[x]];
}
return s;
}啊对了,这题数组要开
1e6而非1e5,不然只有 $30$ 分,望周知。 -
也是板子,不过需要一个转化。
最开始是一棵初始值全部为 $0$ 的树。
install操作:判断 $0\to u$ 路径上有多少个 $0$,并全部改为 $1$。可以再次转换:因为点权只有 $0/1$,故查询操作就是求 $dep_u-\text{query}(1\to u)$。uninstall操作:判断 $u$ 的子树上有多少个 $1$,并全部改为 $0$。
这个人是个不可爱的 BUG 制造机,不过 TA 还是很喜欢瞎搞。
祝您拥有愉快的一天~
